MySQL笔记
前言
MYSQL数据操作语言分为四种
1.DDL(数据定义语言):用来创建数据库中的表、索引、视图、存储过程、触发器等。
2.DML(数据操作语言):用来对表内数据的添加、更新、删除等。
3.DCL(数据控制语言):用于授权/撤销数据库及其字段的权限等。
4.DQL(数据查询语言):用于对表内数据的关键字逻辑查询等。
一、数据库命令
1.登录数据库
语法:mysql -u 用户名 -p
1 | > mysql -u root -p |
2.重启MySQL(linux)
sudo service mysql restart
3.mysql配置文件路径(linux)
/etc/mysql/
4.关闭二进制日志(binlog)功能
/var/lib/mysql/binlog.000001 或 /var/lib/mysql/OFF.000335文件经常过大,占用磁盘空间。找到 MySQL 的配置文件(/etc/mysql/mysql.cnf),在 [mysqld] 部分添加或修改以下行,将关闭 binlog 功能:
1 | [mysqld] |
重启mysql服务后,再运行show variables like’log_%’ 命令。
mysql> show variables like’log_%';
| Variable_name | Value |
|---|---|
| log_bin | OFF |
5.查看mysql版本
$>mysql --version
或
myslq>SELECT VERSION();
6.MySQL各命令说明
命令路径:C:\Program Files\MySQL\MySQL Server 8.0\bin
| 命令 | 说明 |
|---|---|
| mysqld.exe | 是MySQL的主程序,mysqld意思是mysql daemon(后台进程),在后台运行,监听3306端口。 |
| mysql.exe | 是MySQL的命令行工具,是一个客户端软件,可以对任何主机的mysql服务(即后台运行的mysqld)发起连接。 |
| mysqladmin.exe | 是一个执行管理操作的客户端,例如创建或删除数据库,重新加载授权表,将表刷新到磁盘以及重新打开日志文件。 |
| mysqlshow.exe | 是用来查看当前数据库、表、索引、视图等。 |
| mysqldump.exe | 是mysql 数据导出及备份工具。 |
| mysqlslap.exe | 是mysql 性能分析测试工具。 |
二、DDL(Data Definition Language)
1.数据库
(1)创建数据库
1 | mysql> CREATE DATABASE mydatabase; |
(2)查看数据库
1 | -- 查看所有数据库 |
(3)删除数据库
1 | mysql> drop database db1; |
(4)切换数据库
1 | mysql> use db2; |
(5)修改数据库
1 | mysql> alter database db1 charset utf8mb4; |
2.表
(1)创建建
1 | CREATE TABLE departments ( |
- AUTO_INCREMENT:自增。
- PRIMARY KEY:定义主键。
- NOT NULL:不为空。
- FOREIGN KEY(本表外键字段)REFERENCES 其它表(主键):本表外键字段关联其它表主键。
| 类型名称 | 类型 | 说明 |
|---|---|---|
| 整型 | TINYINT | 1字节,有符号-128127,无符号0255(如状态值)。 |
| 整型 | SMALLINT | 2字节,有符号-3276832767,无符号065535。 |
| 整型 | INT | 4字节,有符号-21亿21亿,无符号042亿(常用主键)。 |
| 整型 | BIGINT | 8字节,有符号-922亿亿922亿亿,无符号01844亿亿(超大数据)。 |
| 浮点型 | FLOAT | 4字节,精度约7位(如科学数据)。 |
| 浮点型 | DOUBLE | 8字节,更高精度和范围。 |
| 定点型 | DECIMAL(M,D) | M为总位数(165),D为小数位(030且≤M),如DECIMAL(5,2)存-999.99~999.99。 |
| 定长字符串 | CHAR(L) | L≤255字符,尾部补空格(如短MD5值)。固定长度,检索快但浪费空间。 |
| 变长字符串 | VARCHAR(L): | L≤65535字节,实际有效长度因编码而异(如UTF-8下最大21844字符)。 |
| 文本 | TEXT系列 | TINYTEXT(255字符)、TEXT(64KB)、MEDIUMTEXT(16MB)、LONGTEXT(4GB)。 |
| 二进制 | BLOB | 同TEXT但存二进制数据(如图片)。 |
| 日期 | DATE | 3字节,格式YYYY-MM-DD,范围1000-01-01~9999-12-31。 |
| 时间 | TIME | 36字节,格式HH:MM:SS,范围-838:59:59838:59:59。 |
| 日期 | DATETIME | 5~8字节,格式YYYY-MM-DD HH:MM:SS,范围1000-01-01~9999-12-31,不受时区影响。 |
| 日期 | TIMESTAMP | 4字节,同DATETIME格式但自动更新,范围1970-01-01~2038-01-19,受时区影响。 |
| 年 | YEAR | 1字节,存年份(如2025)。 |
(2)查看表结构
1 | mysql> desc 表名 |
(3)修改表结构
1 | mysql> alter table 表名 rename 新表名 |
(4)删除表
1 | mysql> drop table 表名 |
(5)清空表结构
delete 是清空字段数据。
1 | mysql> truncate 表名 |
三、DML(Data Manipulation Language)
在MySQL管理软件中,可以通过SQL语句中的DML语言来实现数据的操作,
1.插入数据
(1)语法一:
INSERT INTO 表名(字段1,字段2,字段3…字段n) VALUES(值1,值2,值3…值n);
(2)语法二:
INSERT INTO 表名 VALUES (值1,值2,值3…值n);
(3)插入查询结果
INSERT INTO 表名(字段1,字段2,字段3…字段n)
SELECT (字段1,字段2,字段3…字段n) FROM 表2
WHERE …;
1 | INSERT INTO employees (first_name, last_name, email, department_id) VALUES |
2.更新数据
1 | UPDATE table_name |
3.删除数据
使用DELETE vs DROP TABLE:通常,如果你只需要删除表中的数据而保留表结构,使用DELETE。如果你需要彻底删除表(包括所有数据和结构),使用DROP TABLE。
1 | DELETE FROM students WHERE name = 'John Doe'; |
对于重要的数据删除操作,考虑使用事务来确保数据的一致性和完整性。例如,你可以在事务中执行删除操作,然后使用COMMIT来提交事务,或者使用ROLLBACK来回滚事务。
1 | START TRANSACTION; |
四、DCL(Data Control Language)
数据控制语言
1.创建用户
1 | -- 用户只能在指定的IP地址上登陆 |
2.删除用户
1 | mysql> DROP USER 用户名@IP地址; |
3.授权用户
| 级别 | 权限 | 说明 |
|---|---|---|
| user | *.* |
所有数据,所有库下所有表,以及表下的所有字段 |
| db | 数据库1.* |
指定数据库下的所有表,以及表下的所有字段 |
| table_priv | 数据库1.表1 |
指定表的所有字段 |
| columns_priv | 字段1 | 指定字段 |
| 权限列表: |
| 权限类型 | 说明 |
|---|---|
| ALL | 授予用户所有操作权限,不包含 GRANT OPTION 权限,即用户不能将自身权限授予其他用户 |
| ALL PRIVILEGES | 授予用户所有操作权限,包含 GRANT OPTION 权限,即用户可以将自身权限授予其他用户 |
| SELECT | 允许用户执行SELECT查询 |
| INSERT | 允许用户插入数据 |
| UPDATE | 允许用户更新数据 |
| DELETE | 允许用户删除数据 |
| CREATE | 允许用户创建新数据库或表 |
| DROP | 允许用户删除数据库或表 |
| GRANT OPTION | 允许用户将自己拥有的权限授予其他用户 |
| RELOAD | 允许用户执行FLUSH操作(刷新表、日志等) |
| SHUTDOWN | 允许用户关闭MySQL服务器 |
| PROCESS | 允许用户查看当前MySQL服务器的线程信息 |
| FILE | 允许用户读写服务器上的文件 |
| REFERENCES | 允许用户创建外键 |
| INDEX | 允许用户创建和删除索引 |
| ALTER | 允许用户修改表结构 |
| SHOW | DATABASES 允许用户执行SHOW DATABASES查看所有数据库 |
| SUPER | 允许用户执行超级用户操作(如设置全局变量、停止复制等) |
| CREATE TEMPORARY TABLES | 允许用户创建临时表 |
| LOCK TABLES | 允许用户使用LOCK TABLES命令 |
| EXECUTE | 允许用户执行存储过程 |
| REPLICATION SLAVE | 允许用户作为复制从服务器连接 |
| REPLICATION CLIENT | 允许用户查询主从复制服务器信息 |
| CREATE VIEW | 允许用户创建视图 |
| SHOW VIEW | 允许用户执行SHOW CREATE VIEW查看视图定义 |
| CREATE ROUTINE | 允许用户创建存储过程和函数 |
| ALTER ROUTINE | 允许用户修改和删除存储过程和函数 |
| EVENT | 允许用户创建、修改和删除事件 |
| TRIGGER | 允许用户创建和删除触发器 |
| CREATE USER | 允许用户创建、删除和修改用户帐号 |
| ALTER USER | 允许用户修改已有用户的属性(如密码) |
1 | -- 授予用户所有权限,包含GRANT OPTION |
3.撤销授权
1 | -- 撤销用户的所有权限 |
4.查看权限
1 | mysql> SHOW GRANTS FOR '用户名'@'IP地址' |
五、DQL(Data Query Language)
数据查询语言
查询数据
1 | SELECT employees.first_name, employees.last_name, departments.department_name |
1.简单查询
1 | -- 查询 |
2.单表关键字查询
(1) where 约束
where字句中可以使用:
比较运算符:><>= <= <> !=
between 80 and 100 :值在10到20之间
in(80,90,100) :值是10或20或30
like ‘egon%’
pattern可以是%或_,
%表示任意多字符
_表示一个字符
逻辑运算符:在多个条件直接可以使用逻辑运算符 and or not
(2)group by 分组查询
*为何要分组
1、首先明确一点:分组发生在where之后,即分组是基于where之后得到的记录而进行的
2、分组指的是:将所有记录按照某个相同字段进行归类,比如针对员工信息表的职位分组,或者按照性别进行分组等
3、为何要分组呢?
取每个部门的最高工资
取每个部门的员工数
取男人数和女人数
小窍门:‘每’这个字后面的字段,就是我们分组的依据
4、大前提:
可以按照任意字段分组,但是分组完毕后,比如group by post,只能查看post字段,如果想查看组内信息,需要借助于聚合函数
ONLY_FULL_GROUP_BY
mysql >set global sql_mode=“ONLY_FULL_GROUP_BY”;#只能取分组的字段
分组之后,只能取分组的字段,以及每个组聚合结果
ONLY_FULL_GROUP_BY的语义就是确定select target list中的所有列的值都是明确语义,
简单的说来,在ONLY_FULL_GROUP_BY模式下,target list中的值要么是来自于聚集函数的结果,
要么是来自于group by list中的表达式的值。
*使用group by
* 聚合函数
#强调:聚合函数聚合的是组的内容,若是没有分组,则默认一组
示例:
SELECT COUNT() FROM employee;
SELECT COUNT() FROM employee WHERE depart_id=1;
SELECT MAX(salary) FROM employee;
SELECT MIN(salary) FROM employee;
SELECT AVG(salary) FROM employee;
SELECT SUM(salary) FROM employee;
SELECT SUM(salary) FROM employee WHERE depart_id=3;
(3)having 过滤查询
HAVING与WHERE不一样的地方在于!!!
#!!!执行优先级从高到低:where > group by > having
#1. Where 发生在分组group by之前,因而Where中可以有任意字段,但是绝对不能使用聚合函数。
#2. Having发生在分组group by之后,因而Having中可以使用分组的字段,无法直接取到其他字段,可以使用聚合函数
练习题
- 查询各岗位内包含的员工个数小于2的岗位名、岗位内包含员工名字、个数
- 查询各岗位平均薪资大于10000的岗位名、平均工资
- 查询各岗位平均薪资大于10000且小于20000的岗位名、平均工资
select post,group_concat(name),count(id) from employee group by post;
select post,group_concat(name),count(id) from employee group by post having count(id)<2;
select post,avg(salary) from employee group by post having avg(salary)>10000;
select post,avg(salary) from employee group by post having avg(salary) between 10000 and 20000;
(4)查询排序order by
select * from employee order by age asc; #升序
select *from employee order by age desc; #降序
select * from employee order by age asc,id desc # 先按照age升序,如果age相同则按照ID降序
(5)限制查询的记录数:LIMIT
select * from employee limit 3;
select * from employee order by salary desc limit 1;
select * from employee limit 0,5;
#从第0开始,即先查询出第一条,然后包含这一条在内往后查5条
select * from employee limit 5,5;
#从第5开始,即先查询出第6条,然后包含这一条在内往后查5条
(6)使用正则表达式查询
#正则表达式
select * from employee where name like “jin%”;
select from employee where name regexp “^jin”;
select * from employee where name regexp "^jin.(g|n)$"; # 以jin开头,以g或者n结尾的姓名
小结:对字符串匹配的方式
WHERE name = ‘egon’;
WHERE name LIKE ‘yua%’;
WHERE name REGEXP ‘on$’;
3.多表连接查询
(1)多表连接查询
1 | -- 交叉连接:不适用任何匹配条件。生成笛卡尔积 |
(2)符合条件连接查询
查询平均年龄大于30岁的部门名
select department.name,avg(age) from employee inner join department on employee.dep_id = department.id
group by department.name
having avg(age)>30;
(3)子查询
1:子查询是将一个查询语句嵌套在另一个查询语句中。
2:内层查询语句的查询结果,可以为外层查询语句提供查询条件。
3:子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字
4:还可以包含比较运算符:= 、 !=、> 、<等
*带IN关键字的子查询
查询平均年龄在25岁以上的部门名
select * from department where id in
(select dep_id from employee
group by dep_id
having avg(age)>25);
*带比较运算符的子查询
查询大于所以人平均年龄的员工名与年龄
select name,age from employee where age>
(select avg(age) from employee);
查询大于部门内平均年龄的员工名与年龄
select t1.name,t1.age from employee as t1 inner join
(select dep_id,avg(age)as avg_age from employee
group by dep_id)as t2 on t1.dep_id =t2.dep_id where t1.age >t2.avg_age;
*带EXISTS关键字的子查询
select * from employee
where exists
(select id from department where id =200);
关键字逻辑查询语句
SELECT语句关键字的定义顺序
SELECT DISTINCT <select_list>
FROM <left_table>
<join_type> JOIN <right_table>
ON <join_condition>
WHERE <where_condition>
GROUP BY <group_by_list>
HAVING <having_condition>
ORDER BY <order_by_condition>
LIMIT <limit_number>
*SELECT语句关键字的执行顺序
(7) SELECT
(8) DISTINCT <select_list>
(1) FROM <left_table>
(3) <join_type> JOIN <right_table>
(2) ON <join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list>
(6) HAVING <having_condition>
(9) ORDER BY <order_by_condition>
(10) LIMIT <limit_number>
1.先从库,表里找
2.on 后面加两表连接的限制条件
3.将两表连接起来(内左右全等)
4.从约束条件where里过滤出数据
5.然后交给group by 进行分组,
6.分完组后 用having 过滤
7.之后才是运行select 后面的语句,
8.distinct进行去重
9.接着轮到order by 排序
10.limit 最后运行
六、异常处理
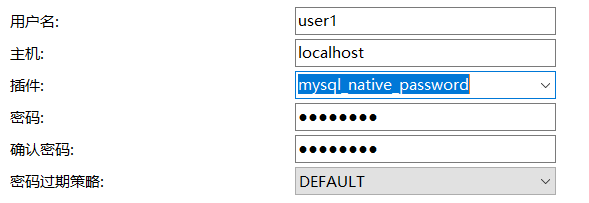
1.连接mysql提示caching-sha2-password异常
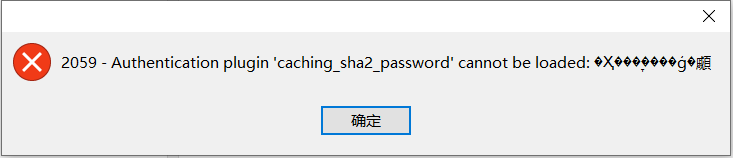
按以下命令顺序执行,修改 caching_sha2_password 为 mysql_native_password ,重新连接。